Les bots de trading font fantasmer. L’image est séduisante : un programme qui travaille 24h/24, sans émotion, qui achète au bon moment et vend au bon moment pendant que vous dormez. La réalité est plus nuancée, mais aussi plus fascinante. Voici ce qu’il faut vraiment comprendre avant de s’y lancer.
Ce qu’est vraiment un bot de trading
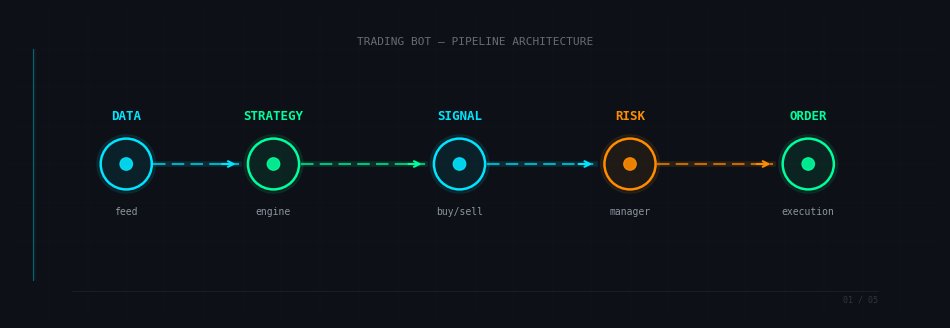
Un bot de trading, c’est un programme qui automatise une décision d’investissement. Rien de magique. Il repose sur quatre briques fondamentales, sans lesquelles rien ne fonctionne.
La source de données. Le bot a besoin de savoir ce qui se passe sur le marché : prix, volumes, carnet d’ordres. Ces données arrivent via une API d’exchange (Binance, Kraken, Interactive Brokers) ou un fournisseur spécialisé. Sans données fiables et récentes, tout le reste est construit sur du sable.
La stratégie. C’est le cerveau du bot. La logique répond à trois questions, quand acheter, quand vendre et combien. C’est là que se joue l’essentiel, et c’est là que la plupart des gens passent trop ou pas assez de temps.
La gestion du risque. L’étape que les débutants négligent systématiquement. Un bot sans gestion du risque finit par tout perdre, même avec une bonne stratégie. Stop-loss, taille de position, exposition maximale, drawdown limite : autant de garde-fous qui séparent un bot amateur d’un bot sérieux.
L’exécution. Envoyer les ordres au broker via API. Ça semble trivial. Ce ne l’est pas. Il faut gérer la latence, les ordres partiellement remplis, les erreurs réseau, les frais, le rate limiting de l’API.
Le workflow type ressemble à ceci :
Données → Indicateurs → Signal → Filtre risque → Ordre → Suivi de position
Les familles de stratégies
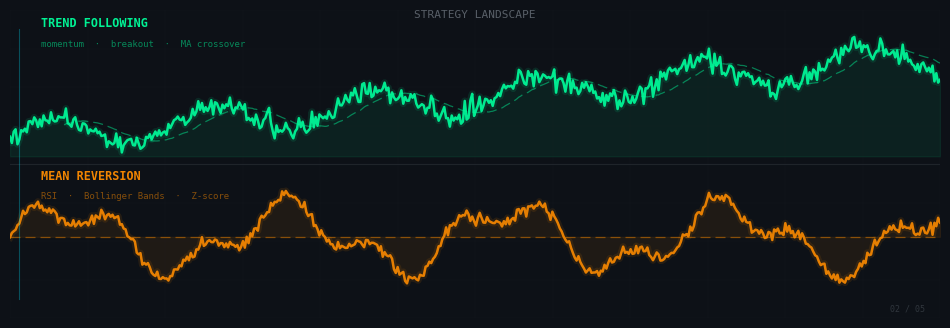
Il n’existe pas une bonne stratégie universelle. Il en existe plusieurs familles, chacune reposant sur une hypothèse différente sur le comportement des marchés.
Le suivi de tendance
Hypothèse : un prix qui monte a tendance à continuer de monter. On achète quand une tendance s’installe, on vend quand elle s’inverse. Les indicateurs classiques sont les moyennes mobiles croisées, le MACD, ou les stratégies de breakout comme la méthode Donchian.
La stratégie des “Turtle Traders”, popularisée par Richard Dennis en 1983, en est un exemple célèbre. Le Système 1 consiste à acheter quand le prix dépasse son plus-haut des 20 derniers jours, puis à vendre quand il passe sous son plus-bas des 10 derniers. Le Système 2, à plus long terme, entre sur un plus-haut de 55 jours et sort sur un plus-bas de 20 jours. Dans les deux cas, chaque trade était protégé par un stop fixe à 2N, soit deux fois la volatilité quotidienne moyenne. Peu de paramètres, des règles claires et des traders amateurs transformés en professionnels rentables. Les Turtles ont généré environ 175 millions de dollars de profits en cinq ans.
Force de cette approche : elle capture les grandes tendances, avec des gains potentiellement importants. Faiblesse : elle souffre en marché sans direction, avec beaucoup de faux signaux et une tendance à rentrer tard et sortir tard.
Le retour à la moyenne
Hypothèse opposée : le prix oscille autour d’une valeur “juste” et revient toujours vers elle quand il s’en éloigne. On achète quand le marché est survendu (RSI sous 30, prix sous la bande de Bollinger basse), on vend quand il est suracheté.
Cette approche produit beaucoup de petits gains en marché calme. Mais elle est catastrophique face à une vraie tendance. Acheter parce que “c’est tombé bas” et voir le prix continuer de chuter, c’est ce qu’on appelle “catching a falling knife”. Un filtre de tendance (par exemple ne faire du mean reversion qu’en marché latéral) est souvent indispensable.
L’arbitrage
Hypothèse : le même actif doit avoir le même prix partout. Si une divergence apparaît, on l’exploite. Mais toutes les formes d’arbitrage ne se ressemblent pas.
L’arbitrage pur (spatial ou triangulaire) exploite des écarts de prix immédiats entre marchés. En théorie, il évite le risque directionnel. En pratique, il reste inaccessible. Les marges sont minuscules, la vitesse est absolue et ces opportunités sont chassées par des firmes HFT en quelques microsecondes grâce à des serveurs co-localisés. Pour un particulier, oubliez.
L’arbitrage statistique (pair trading) fonctionne autrement. On parie que deux actifs historiquement corrélés qui divergent temporairement vont finir par se rapprocher. Ce type de stratégie peut s’étendre sur des heures ou des jours, ne nécessite pas d’infrastructure HFT et reste un domaine actif pour les quants individuels. Le risque principal tient à la corrélation, qui peut se briser définitivement.
Le market making
Le market maker fournit de la liquidité : il pose simultanément un ordre d’achat sous le prix et un ordre de vente au-dessus. Si les deux s’exécutent, il empoche le spread. Revenu régulier, peu directionnel. Mais il s’expose au “toxic flow” : quand le marché bouge dans un sens, un seul côté s’exécute et il se retrouve avec une position perdante. Terrain de jeu des firmes spécialisées (Jump, Citadel, Wintermute).
Le momentum et le machine learning
Le momentum se décline en deux variantes. Le momentum cross-sectionnel consiste à classer un panier d’actifs par performance récente, acheter les meilleurs, vendre les moins bons : une stratégie académiquement documentée depuis Jegadeesh et Titman (Returns to Buying Winners and Selling Losers, Journal of Finance, 1993), qui a historiquement fonctionné sur la plupart des classes d’actifs. Le momentum de série temporelle évalue la performance absolue d’un actif par rapport à son propre historique : des recherches académiques récentes montrent qu’il est souvent supérieur au momentum cross-sectionnel en termes de rendement ajusté au risque.
Quant au machine learning appliqué au trading, la réalité est décevante. Une grande majorité des projets échouent en live. Les marchés sont non-stationnaires, ce qui marchait hier peut ne plus marcher demain, et les modèles apprennent le bruit historique plutôt que les vrais signaux. À réserver à ceux qui maîtrisent vraiment la statistique.
La règle d’or : la simplicité gagne
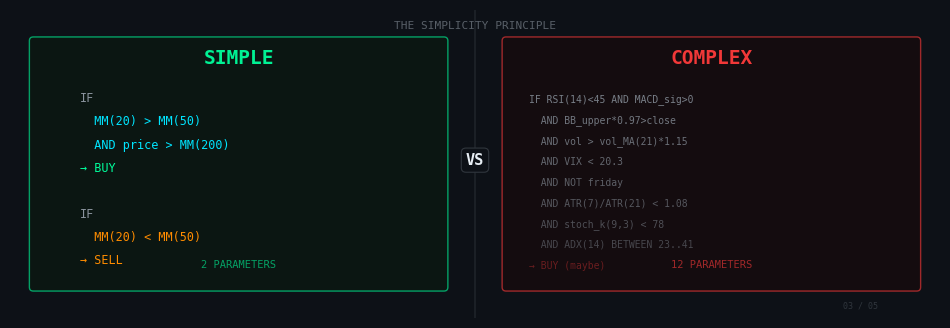
Il y a un paradoxe contre-intuitif dans le trading algorithmique : les stratégies simples battent presque toujours les stratégies complexes. Pas parce que les marchés sont simples, mais pour une raison purement statistique.
Une stratégie simple, c’est une stratégie qui répond à quatre questions en une phrase chacune :
- Quand j’achète ?
- Quand je vends ?
- Combien j’achète ?
- Quel est mon stop ?
Si vous avez besoin de plus de quatre lignes pour décrire votre stratégie, elle commence à être complexe. Et plus elle est complexe, plus elle a de paramètres. Et plus elle a de paramètres, plus elle peut s’ajuster parfaitement aux données historiques. Et cette perfection sur le passé n’a aucune valeur prédictive.
Une stratégie à deux paramètres qui fait +15% par an sur 20 ans avec un drawdown maximum de 25% est infiniment plus crédible qu’une stratégie à douze paramètres qui affiche +40% par an avec 8% de drawdown sur les mêmes données. La première a probablement capté un phénomène réel. La seconde a probablement appris le bruit.
Le bon test mental tient en une question. Est-ce que la stratégie fonctionne sur cinq années différentes, sur cinq marchés différents ? Si elle ne marche que sur Bitcoin entre 2020 et 2021, elle décrit surtout une période exceptionnelle.
Le backtest : nécessaire et traître
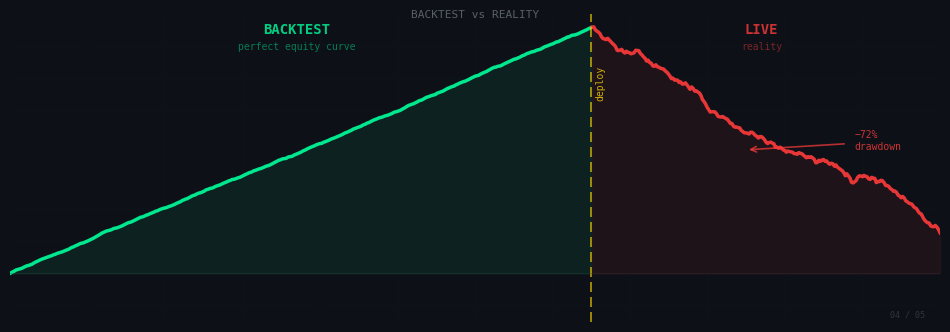
Avant de risquer un euro, on valide la stratégie sur des données historiques. C’est le backtest. C’est l’étape la plus importante et, ironiquement, la plus dangereuse si elle est mal faite. Un mauvais backtest donne une fausse confiance, ce qui est bien plus dangereux qu’aucun backtest du tout.
Les métriques qui comptent
Le rendement total ne suffit pas. Ce qui compte vraiment :
- Le CAGR (rendement annualisé composé) : plus parlant que le rendement brut
- Le drawdown maximum : la plus grosse perte du pic au creux. C’est ce qui vous dira si vous pourrez psychologiquement tenir la stratégie en live
- Le Sharpe ratio : rendement rapporté à la volatilité. Les stratégies robustes de la littérature académique affichent souvent entre 0,5 et 0,8. Dépasser 1 est un objectif ambitieux, pas une norme. Au-dessus de 3, méfiez-vous sérieusement de l’overfitting
- Le Calmar ratio : CAGR divisé par le drawdown max. Mon préféré. Au-dessus de 0,5, acceptable
- Le nombre de trades : une stratégie qui a produit 12 trades en 10 ans n’est pas statistiquement significative. Visez au moins 100, idéalement 500+
Les pièges qui ruinent tout
Le look-ahead bias. Le plus sournois. Vous utilisez, sans vous en rendre compte, une donnée qui n’était pas disponible au moment du trade. Par exemple, calculer la moyenne mobile du jour en incluant le close du jour même, puis décider d’acheter ce même jour. En pratique, le close n’est connu qu’à la clôture. Vous trichiez avec le futur.
Le survivorship bias. Vous testez votre stratégie crypto sur le top 100 d’aujourd’hui. Mais en 2018, ce top 100 était composé de nombreux projets qui ont depuis disparu. Votre stratégie a “prédit” les survivants, ce qu’elle ne pourra pas faire en live.
L’overfitting. Vous testez 50 combinaisons de paramètres et choisissez la meilleure. Sur 50 essais, certains paraîtront brillants par pur hasard. Solution : le walk-forward testing (optimiser sur une période, valider sur la suivante) et garder un jeu de données “sacré” qu’on ne touche qu’une seule fois pour le test final.
Les frais et le slippage ignorés. Vos trades simulés s’exécutent au prix exact, sans frais. Dans la vraie vie, 0,1% par trade en crypto, un spread bid/ask, un slippage à l’entrée. Une stratégie qui fait +15% par an hors frais peut faire 0% avec des conditions réalistes. Règle pratique : simulez avec des frais deux fois supérieurs aux frais réels. Si ça reste rentable, c’est bon signe.
La sélection des stratégies publiées. Vous testez 30 idées, une marche bien, vous vous concentrez sur celle-là. Mais sur 30 stratégies aléatoires, il y en aura toujours une qui semble bonne par hasard. Gardez un journal de tout ce que vous testez.
La méthodologie rigoureuse
Une approche sérieuse ressemble à ceci :
- Séparez dès le départ vos données en trois blocs : développement (2015-2020), validation (2021-2022), données sacrées intouchables (2023-2024)
- Développez et optimisez uniquement sur le bloc de développement
- Validez sur 2021-2022 pour vérifier que ça tient
- Appliquez au bloc sacré une seule fois. Si ça ne marche pas, vous repartez de zéro avec une autre idée, vous n’avez pas le droit de retoucher
- Passez en paper trading pendant suffisamment longtemps avant de risquer tout argent réel
- Commencez en live avec une fraction du capital prévu
Le mantra à retenir : un backtest n’est pas une preuve que la stratégie marchera. C’est seulement une preuve qu’elle aurait pu marcher.
L’architecture d’un bot sérieux
Sur le plan technique, un bot bien conçu est modulaire. Chaque brique est indépendante et remplaçable.
Le data feed reçoit les prix en temps réel via WebSocket et les données historiques via REST. Il normalise tout dans un format interne unique, peu importe la source.
Le storage a deux niveaux, avec un cache en mémoire (Redis ou simple dictionnaire Python) pour l’état courant accessible en microsecondes et une base de données (PostgreSQL, TimescaleDB) pour l’historique des trades et les performances.
Le strategy engine consomme les données, calcule les indicateurs, émet des signaux BUY, SELL ou HOLD. Il est conçu comme une fonction pure : données en entrée, signal en sortie. Ça permet de le tester facilement et de changer de stratégie sans toucher au reste.
Le risk manager se place entre la stratégie et l’exécution. Il vérifie la taille de position, l’exposition totale, le drawdown depuis le début de la journée, les conditions de marché anormales. S’il refuse, l’ordre n’est pas envoyé. C’est le garde-fou.
Le monitoring : logs structurés, métriques, alertes (Telegram ou Discord si quelque chose part en vrille) et surtout un kill switch pour tout arrêter immédiatement.
Trois principes d’architecture à ne jamais oublier :
- Event-driven : le bot réagit à des événements (nouveau prix, ordre exécuté, timer) plutôt que de tourner en boucle. Plus propre, plus testable.
- État reconstructible : si le bot crashe, il doit pouvoir redémarrer en retrouvant son état complet en lisant la base de données. Aucun état uniquement en mémoire.
- Séparation backtest/live : le même code de stratégie doit pouvoir tourner sur des données historiques ou en temps réel. On y arrive en abstrayant la source de données.
Concrètement, en voici un exemple d’implementation : https://github.com/hansipie/tradbot
La réalité brutale
La majorité des bots amateurs perdent de l’argent. Les marchés sont efficaces, les frais grignotent les marges et ce qui marche en backtest échoue souvent en live.
Les bots qui gagnent vraiment sont soit très simples et bien gérés en risque, soit développés par des firmes professionnelles avec une infrastructure et des données hors de portée du particulier. Le trading haute fréquence, l’arbitrage pur, le market making professionnel : ce sont des jeux d’équipes avec des serveurs co-localisés dans les datacenters des exchanges, pas des projets de week-end.
Ce qui reste accessible tient plutôt aux stratégies swing trading sur des horizons de quelques heures à quelques jours, avec peu de paramètres, une gestion du risque rigoureuse et beaucoup d’humilité face au backtest.
La bonne question à se poser avant de déployer un euro n’est pas “est-ce que mon backtest est beau ?”, mais “est-ce que je comprends pourquoi cette stratégie gagne et est-ce que ce mécanisme a des chances d’exister encore dans six mois ?”
Si vous ne pouvez pas répondre à cette question clairement, le backtest ne compte pas.